To check whether a given string is a substring of another string is a very common programming operation. However, I was not able to find a succinct, complete description of some of the algorithms behind substring searching. Hopefully, readers will find this post and the associated code useful!
The fundamental string searching (matching) problem is defined as follows: given two strings - a text and a pattern, determine whether the pattern appears in the text. The problem is also known as "the needle in a haystack problem."
The Naive Method
The idea is straightforward -- for every position in the text, consider it a starting position of the pattern and see if you get a match.
The fundamental string searching (matching) problem is defined as follows: given two strings - a text and a pattern, determine whether the pattern appears in the text. The problem is also known as "the needle in a haystack problem."
The Naive Method
The idea is straightforward -- for every position in the text, consider it a starting position of the pattern and see if you get a match.

The naive method exhibits a worst case time complexity of O(n*m) because we potentially compare each element of the text with every element of the pattern. In other words, the naive method generates EVERY possible substring of the text and compares it with pattern.
Rabin-Karp Algorithm (RK)
Rabin–Karp algorithm is a string searching algorithm created by Michael O. Rabin and Richard M. Karp in 1987. The Rabin–Karp algorithm focuses on speeding up the generation of a substring derived from text and its comparison to the pattern with the help of Hash Function.
The method behind the RK algorithm is :
Let the Pattern be P (of length L) and the text be T (of length n).
In other words, the RK algorithm simply hashes EVERY possible substring on the text and compares it with the hash of the pattern. At this point you must be wondering how this is any better than the naive implementation. But as we shall see shortly, the RK algorithm improves its run time by using a rolling hash. To understand what a rolling hash is, we first need to know what a typical hashing function would look like.
The Choice of Hash Function
Let us take a step back from string and walk through the 3 step above by considering integer arrays.
Let the pattern P and the text T be:
P = [9,0,2,1,0]
T=[4,8,9,0,
The length 5 substrings of T would be:
S0 = [9,8,7,1,2]
S1 = [8,7,1,2,3]
S2 = [7,1,2,3,4]
.......
For each of these substring, our hash function to generate a hash value (an integer). Let the size of the Hash Table be m. Our hash function will be:
Rabin-Karp Algorithm (RK)
Rabin–Karp algorithm is a string searching algorithm created by Michael O. Rabin and Richard M. Karp in 1987. The Rabin–Karp algorithm focuses on speeding up the generation of a substring derived from text and its comparison to the pattern with the help of Hash Function.
The method behind the RK algorithm is :
Let the Pattern be P (of length L) and the text be T (of length n).
- Hash P to get h(P) [This takes O(L) time]
- Iterate through all length L substrings of T, hashing those substrings and comparing to h(P) [ This takes O(n*L) ]
- If a substring hash value does match h(P), do a string comparison on that substring and P, stopping if they do match and continuing if they do not. [ O(L) ]
In other words, the RK algorithm simply hashes EVERY possible substring on the text and compares it with the hash of the pattern. At this point you must be wondering how this is any better than the naive implementation. But as we shall see shortly, the RK algorithm improves its run time by using a rolling hash. To understand what a rolling hash is, we first need to know what a typical hashing function would look like.
The Choice of Hash Function
- It should be easy to compare two hash values. For example, if the range of the hash function is a set of sufficiently small nonnegative integers, then two hash values can be compared with a single machine instruction
- The number of false positives induced by the hash function should be similar to that achieved by a “random” function. If the range of the hash function is of size m, we’d like each hash value to be achieved by approximately the same number of L-symbol strings (where L is the length of the pattern)
- It should be easy (e.g., a constant number of machine instructions) to compute h(Si+1) given h(Si)
Let us take a step back from string and walk through the 3 step above by considering integer arrays.
Let the pattern P and the text T be:
P = [9,0,2,1,0]
T=[4,8,9,0,
The length 5 substrings of T would be:
S0 = [9,8,7,1,2]
S1 = [8,7,1,2,3]
S2 = [7,1,2,3,4]
.......
For each of these substring, our hash function to generate a hash value (an integer). Let the size of the Hash Table be m. Our hash function will be:
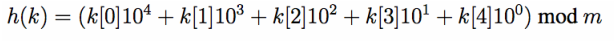
In other words, we will take the length 5 array of integers and concatenate the integers into
a 5 digit number, then take the number mod m. (we take mod m so that we can narrow down the 5 digit number into a number in the range of 0 - m. Remember the hash number generated is used as an index into the hash table of size m).
Now h(P) is 90210 mod m
h(S0) is 48902 mod m
h(S1) is 89021 mod m
Do you see the relationship between h(S0) and h(S1) ? In fact, we can generate h(S1) by using h(S0)! We start with 48902, remove the first digit to get 8902, multiply by 10 to get 89020, and then add the next digit to get 89021. i.e
a 5 digit number, then take the number mod m. (we take mod m so that we can narrow down the 5 digit number into a number in the range of 0 - m. Remember the hash number generated is used as an index into the hash table of size m).
Now h(P) is 90210 mod m
h(S0) is 48902 mod m
h(S1) is 89021 mod m
Do you see the relationship between h(S0) and h(S1) ? In fact, we can generate h(S1) by using h(S0)! We start with 48902, remove the first digit to get 8902, multiply by 10 to get 89020, and then add the next digit to get 89021. i.e
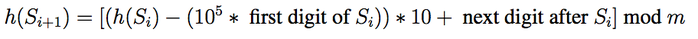
We can now imagine a window sliding over all the substrings in S. Calculating the hash value of the next substring only touches 2 elements: the element leaving the window and the element
entering the window. Finding the hash value of the next substring is now a O(1) operation.
In this numerical example, we looked at single digit integers and set our base b = 10 so that
we can interpret the arithmetic easier. To generalize for other base b and substrings of length L, our hash function is:
entering the window. Finding the hash value of the next substring is now a O(1) operation.
In this numerical example, we looked at single digit integers and set our base b = 10 so that
we can interpret the arithmetic easier. To generalize for other base b and substrings of length L, our hash function is:
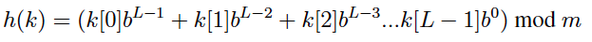
and the formula to calculate the next Hash would be:
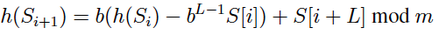
Back to Strings
Since strings can be interpreted as an array of integers, we can apply the same method we used on numbers to the initial problem, improving the runtime. The algorithm steps are now:
Now we need to choose the value of the base b (see the formula highlighted in the black box). b is often chosen to be a power of 2 so that b^L-1 (b power L-1) can be computed fast (example: b=16 or b=32). But what happens if b^L-1 becomes too large? This can easily cause an integer overflow. Which is why we need mod m.
What about m? What should be the size of the Hash table? m is often a prime number.
I was lucky to find this excellent discussion on StackOverflow about the value of m and the "nature of math" and strongly suggest that you read it:
http://stackoverflow.com/questions/1145217/why-should-hash-functions-use-a-prime-number-modulus
Let us now summarize our constants:
We can now proceed with our algorithm:
Algorithm: RabinKarpPatternSearch (pattern, text)
Input: pattern array of length L, text array of length n
Code: You may find the complete Java implementation at:
https://github.com/sarveshsaran/RabinKarp
Since strings can be interpreted as an array of integers, we can apply the same method we used on numbers to the initial problem, improving the runtime. The algorithm steps are now:
- Hash P to get h(P) [ O(L) ]
- Hash the first substring of S of length L [O(L)]
- Use the rolling hash method to calculate the subsequent O(n) substrings in S, comparing the hash values to h(P) [This is O(n) ]
- If a substring hash value does match h(P), do a string comparison on that substring and P, stopping if they do match and continuing if they do not. [O(L)] (Why? because of Collisions! We still need to check if the strings match exactly, even though their hash values are same.)
Now we need to choose the value of the base b (see the formula highlighted in the black box). b is often chosen to be a power of 2 so that b^L-1 (b power L-1) can be computed fast (example: b=16 or b=32). But what happens if b^L-1 becomes too large? This can easily cause an integer overflow. Which is why we need mod m.
What about m? What should be the size of the Hash table? m is often a prime number.
I was lucky to find this excellent discussion on StackOverflow about the value of m and the "nature of math" and strongly suggest that you read it:
http://stackoverflow.com/questions/1145217/why-should-hash-functions-use-a-prime-number-modulus
Let us now summarize our constants:
- Let us choose b to be 256 ( a power of 2)
- m should be a prime number. We will generate this prime number using the Class BigInteger (java.math)
- We will precompute b^L-1 mod m (again check the formula in the highlighted box). Instead of repeatedly computing b^L-1 to generate the rolling hash values, we should rather precompute this.
- So let b^L-1 mod m be R
We can now proceed with our algorithm:
Algorithm: RabinKarpPatternSearch (pattern, text)
Input: pattern array of length L, text array of length n
- patternHash = computePatternSignature (pattern);
- Optimization: compute b^L-1 mod m just once. So R = b^L-1 mod m
- texthash = compute signature of text[0]...text[L-1] (i.e compute the hash of the first substring of the text).
- textCursor = 0;
- while textCursor != end of text
- if textHash = patternHash // Potential match.
- if exact_match (pattern, text, textCursor) // Match found
- return textCursor
- endif
- // Different strings with same signature, so continue search.
- endif
- textCursor = textCursor + 1
- //Use O(1) computation to compute next signature:
- textHash = compute signature of text[textCursor],...,text[textCursor+L-1]
- endwhile
- return -1
Code: You may find the complete Java implementation at:
https://github.com/sarveshsaran/RabinKarp
 RSS Feed
RSS Feed
