
As an avid user of Reddit, I was inspired to study the network structure of Reddit for a social network analysis class.
Reddit is a social news website driven by user content. Reddit is a data-rich website with a complex network structure. Reddit comment threads may trail for more than two weeks and one single post can easily exceed 1000 comments, which are mainly replies to other comments rather than direct responses to the original posts. There is hence an implicit relationship based on shared interests between the comments, and between the comment and the post, which can be used to construct a social network.
Step 1: Data Collection
Currently no large Reddit datasets exist. Thus a key part of this project was to crawl Reddit and retrieve the content. There are three parts to crawling Reddit:
1. Get list of subreddits
2. Get list of submissions for each subreddit
3. Get content and comments for each submission
Reddit’s threaded comment system provides the most interesting data. Each comment contains the user, a timestamp, a list of replies in the form of comments, and the score (up votes minus down votes) for that individual comment. At the end of the crawling phase, I collected the profiles of 229254 users, with 696165 comments from 6864 posts.
The crawler was written using Python and the PRAW library. PRAW, an acronym for “Python Reddit API Wrapper”, is a python package that allows for simple access to Reddit’s API. PRAW aims to be as easy to use as possible and is designed to follow all of reddit’s API rules.
Step2 : Visualizing the Discussion Structure : Radial Tree to the Rescue
Even though Reddit has a convenient interface for participating in discussions, the ability to examine the structure of the comments from the comment list is very limited. However, a special tree representation (as shown in [Gomez et. al.] for the post comments provides a convenient way to visualize the discussion structure. The central node is defined as the post itself. Any comments made directly on this post are attached as children in a radial pattern around this central node. Nested comments are attached similarly to their parent until the entire comment tree is visible. This tree structure grows outward from the central node as the discussion takes place over time. The figure below shows a fairly popular post that received over 750 comments represented with the radial tree structure. The next figure shows a post with a similar number of comments, however, this post has very few discussions reaching deeper nesting levels, and almost all of the comments appear as direct replies to the post.
Reddit is a social news website driven by user content. Reddit is a data-rich website with a complex network structure. Reddit comment threads may trail for more than two weeks and one single post can easily exceed 1000 comments, which are mainly replies to other comments rather than direct responses to the original posts. There is hence an implicit relationship based on shared interests between the comments, and between the comment and the post, which can be used to construct a social network.
Step 1: Data Collection
Currently no large Reddit datasets exist. Thus a key part of this project was to crawl Reddit and retrieve the content. There are three parts to crawling Reddit:
1. Get list of subreddits
2. Get list of submissions for each subreddit
3. Get content and comments for each submission
Reddit’s threaded comment system provides the most interesting data. Each comment contains the user, a timestamp, a list of replies in the form of comments, and the score (up votes minus down votes) for that individual comment. At the end of the crawling phase, I collected the profiles of 229254 users, with 696165 comments from 6864 posts.
The crawler was written using Python and the PRAW library. PRAW, an acronym for “Python Reddit API Wrapper”, is a python package that allows for simple access to Reddit’s API. PRAW aims to be as easy to use as possible and is designed to follow all of reddit’s API rules.
Step2 : Visualizing the Discussion Structure : Radial Tree to the Rescue
Even though Reddit has a convenient interface for participating in discussions, the ability to examine the structure of the comments from the comment list is very limited. However, a special tree representation (as shown in [Gomez et. al.] for the post comments provides a convenient way to visualize the discussion structure. The central node is defined as the post itself. Any comments made directly on this post are attached as children in a radial pattern around this central node. Nested comments are attached similarly to their parent until the entire comment tree is visible. This tree structure grows outward from the central node as the discussion takes place over time. The figure below shows a fairly popular post that received over 750 comments represented with the radial tree structure. The next figure shows a post with a similar number of comments, however, this post has very few discussions reaching deeper nesting levels, and almost all of the comments appear as direct replies to the post.
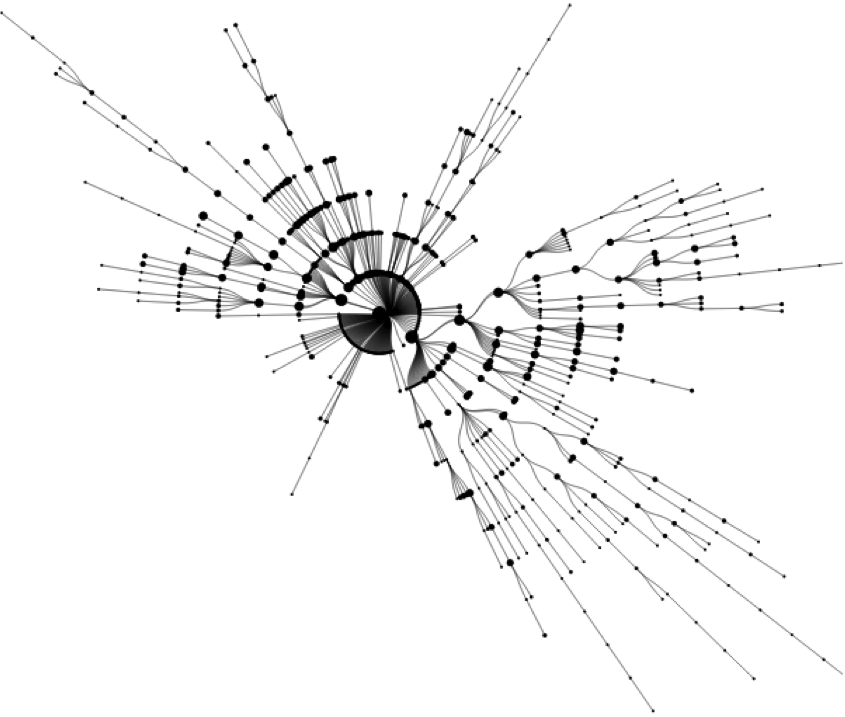
Fig 1. Radial Tree : Post with 750 Comments
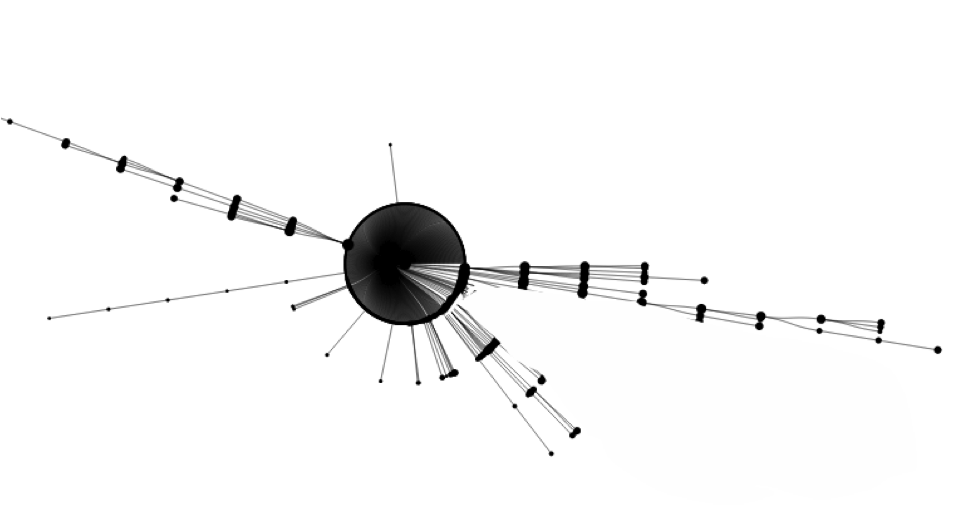
Fig 2. A Post with 750 comments but not a lot of "discussion"
The structure of the trees is highly heterogeneous. For some posts, the tree reaches a high depth with very few comments due to intense discussion among a few users. In other posts, there are hundreds of comments in the first two nesting levels and very few outside of that. Sometimes the majority of the discussion actually happens in one of the child threads and the tree has a skewed appearance.
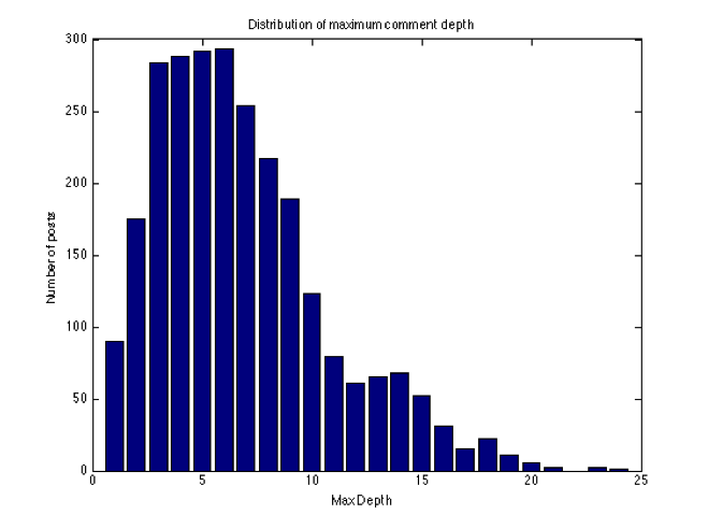
Next, we plot the distribution of comment depths for all posts. As you can see, the majority of comments are made in the first few nesting levels, however, we can see that there is a substantial amount of discussion going on in the deeper levels.
Next, we plot the distribution of comment depths for all posts. As you can see, the majority of comments are made in the first few nesting levels, however, we can see that there is a substantial amount of discussion going on in the deeper levels.
Step 3: Measuring Controversy
What is Reddit without controversy? But how exactly do we capture "controversy"? Reddit allows you to sort posts in several ways. “Top” lists the most popular posts by number of comments, “Hot” lists recently popular posts, and “Controversial” lists posts with a lot of up-votes and down-votes but a low overall score.
There are many ways to define how controversial a post is. Perhaps the most simple is to define it as the total number of comments. Posts that triggered a lot of discussion are probably controversial. However, while a post might have lots of comments, there may not be much reciprocal discussion. The maximum depth a post reaches, therefore, seems like a better measure. This too has problems however. If two users get engaged in a long discussion, the corresponding post will be considered highly controversial even if all the other comments appear in the first few nesting levels. We would like a method to account for these two types of bias. The measure we will use is h-index, as shown in [Gomez et.al.].
What is the h-index?
We used the following adapted version of h-index: The h-index of a post is the deepest nesting level of the radial tree with at least h comments. For example, the post in Figure 2 has an h-index of 4. If ranking just by number of comments, it would be 2nd, however, using h-index, it’s ranking falls to 153. This post is one of many that have a low h-index despite having a large number of comments. The h-index captures the difference between Figure 1 and Figure 2, unlike using the number of comments or the maximum depth.
When ranking posts by h-index, we need a way to break the ties because many posts have the same h-index values. I used the same method as [Gomez et.al], which is to prioritize the posts which have reached higher h-index values with fewer comments.
What is Reddit without controversy? But how exactly do we capture "controversy"? Reddit allows you to sort posts in several ways. “Top” lists the most popular posts by number of comments, “Hot” lists recently popular posts, and “Controversial” lists posts with a lot of up-votes and down-votes but a low overall score.
There are many ways to define how controversial a post is. Perhaps the most simple is to define it as the total number of comments. Posts that triggered a lot of discussion are probably controversial. However, while a post might have lots of comments, there may not be much reciprocal discussion. The maximum depth a post reaches, therefore, seems like a better measure. This too has problems however. If two users get engaged in a long discussion, the corresponding post will be considered highly controversial even if all the other comments appear in the first few nesting levels. We would like a method to account for these two types of bias. The measure we will use is h-index, as shown in [Gomez et.al.].
What is the h-index?
We used the following adapted version of h-index: The h-index of a post is the deepest nesting level of the radial tree with at least h comments. For example, the post in Figure 2 has an h-index of 4. If ranking just by number of comments, it would be 2nd, however, using h-index, it’s ranking falls to 153. This post is one of many that have a low h-index despite having a large number of comments. The h-index captures the difference between Figure 1 and Figure 2, unlike using the number of comments or the maximum depth.
When ranking posts by h-index, we need a way to break the ties because many posts have the same h-index values. I used the same method as [Gomez et.al], which is to prioritize the posts which have reached higher h-index values with fewer comments.
 RSS Feed
RSS Feed
