What is a column-oriented database (or a column store) and how is it different from a row oriented one?
This article will explore the key differences and tradeoffs between the two at a fairly high level (but with enough technical information!). It is important to understand that Columnar database is a concept rather a particular architecture/implementation. The exact architecture, partitioning, layout differs from one implementation (say HBASE) to other (say Cassandra).
How do they differ from relational databases?
A relation database is a logical concept. A columnar database, or column-store, is a physical concept. Column oriented databases may be relational or not, just as row oriented databases may adhere more or less to relational principles.
Let us look at an example:
Here's a representation on a table called Sales with Columns (Date, Store,Product,Customer, Price) in a column Store and a row store.
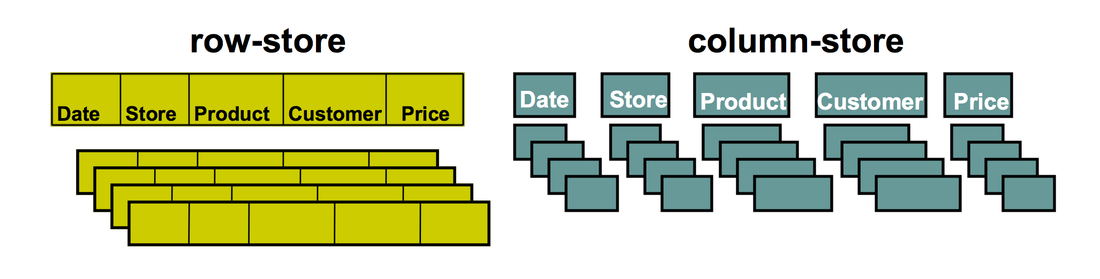
This is how the sales table will be stored in a row oriented database :
On Disk:
Date Store Product Customer Price
-------------------------------------------------------------
2015-09-1 store1 product1 customer1 1.0
2015-09-1 store1 product2 customer2 4.0
2015-09-2 store2 product2 customer3 1.0
And in memory representation (assume each field is 8 bytes for simplicity and deal with the comma delimiter)
Address0 : 2015-09-1,store1,product1,customer1,1.0
Address40: 2015-09-1,store1,product2,customer2,4.0
Adressss80: 2015-09-2,store2,product2,customer3,1.0
The same table in a column store :
On Disk:
Date
2015-09-1
2015-09-1
2015-09-2
Store
store1
store1
store2
Product
product1
product2
product2
Cutomer
customer1
customer2
customer3
Price
1.0
4.0
1.0
In Memory:
Address0: 2015-09-1,2015-09-2
Address16:store1,store2
Address32:product1,product2
Address64: customer1,customer2,customer3
Address88:1.0,4.0,1.0
Now lets talk about an important aspects of database performance:
Locality: Are the attributes we want to fetch next to each other? For example, imagine I want to sum the total sales (for all stores) on 2015-09-1. In a columnar store, I only need to look at the memory block from address 88 onwards. The probability of these blocks bring in memory (cache) will be fairly high.
Tradeoffs:
There are several interesting tradeofs depending on the access patterns. If data is stored on the disk, then if a query needs to access only a single record (i.e., all or some of the attributes of a single row of a table), a column-store will have to seek several times (to all columns/files of the table referenced in the query) to read just this single record. However, if a query needs to access many records, then large swaths of entire columns can be read, amortizing the seeks to the different columns.
In a conventional row-store, in contrast, if a query needs to access a single record, only one seek is needed as the whole record is stored contiguously, and the overhead of reading all the attributes of the record (rather than just the relevant attributes requested by the current query) will be negligible relative to the seek time. However, as more and more records are accessed, the transfer time begins to dominate the seek time, and a column-oriented approach begins to perform better than a row-oriented approach. For this reason, column-stores are typically used in analytic applications, with queries that scan a large fraction of individual tables and compute aggregates or other statistics over them.
On Disk:
Date Store Product Customer Price
-------------------------------------------------------------
2015-09-1 store1 product1 customer1 1.0
2015-09-1 store1 product2 customer2 4.0
2015-09-2 store2 product2 customer3 1.0
And in memory representation (assume each field is 8 bytes for simplicity and deal with the comma delimiter)
Address0 : 2015-09-1,store1,product1,customer1,1.0
Address40: 2015-09-1,store1,product2,customer2,4.0
Adressss80: 2015-09-2,store2,product2,customer3,1.0
The same table in a column store :
On Disk:
Date
2015-09-1
2015-09-1
2015-09-2
Store
store1
store1
store2
Product
product1
product2
product2
Cutomer
customer1
customer2
customer3
Price
1.0
4.0
1.0
In Memory:
Address0: 2015-09-1,2015-09-2
Address16:store1,store2
Address32:product1,product2
Address64: customer1,customer2,customer3
Address88:1.0,4.0,1.0
- Column-store systems completely vertically partition a database into a collection of individual columns that are stored separately.
- Each column is stored separately on disk
Now lets talk about an important aspects of database performance:
Locality: Are the attributes we want to fetch next to each other? For example, imagine I want to sum the total sales (for all stores) on 2015-09-1. In a columnar store, I only need to look at the memory block from address 88 onwards. The probability of these blocks bring in memory (cache) will be fairly high.
Tradeoffs:
There are several interesting tradeofs depending on the access patterns. If data is stored on the disk, then if a query needs to access only a single record (i.e., all or some of the attributes of a single row of a table), a column-store will have to seek several times (to all columns/files of the table referenced in the query) to read just this single record. However, if a query needs to access many records, then large swaths of entire columns can be read, amortizing the seeks to the different columns.
In a conventional row-store, in contrast, if a query needs to access a single record, only one seek is needed as the whole record is stored contiguously, and the overhead of reading all the attributes of the record (rather than just the relevant attributes requested by the current query) will be negligible relative to the seek time. However, as more and more records are accessed, the transfer time begins to dominate the seek time, and a column-oriented approach begins to perform better than a row-oriented approach. For this reason, column-stores are typically used in analytic applications, with queries that scan a large fraction of individual tables and compute aggregates or other statistics over them.
 RSS Feed
RSS Feed
